


robots.txt 是什麼?對 SEO 有什麼幫助?
根據 Google 官方文件的說明,robots.txt 是含特定規則的簡單文字檔,是用以告知搜尋引擎爬蟲你的網站中有哪些頁面是不需要被檢索的。操作 SEO 時,我們大多希望網頁進可能被檢索收錄來取得良好排名,但有些網頁對於 SEO 沒有幫助、甚至可能使排名變差,這時候就可以使用 robots.txt 避免檢索,以利減輕搜尋引擎爬蟲負擔、提升爬蟲爬取的速度,讓爬蟲把力氣花再更重要的頁面上。
Google 搜尋引擎運作原理補充
搜尋引擎爬蟲的運行可大致分為檢索(Crawling)、索引(Indexing)、用戶搜尋(Searching)、排名(Rankking)四大流程,robots.txt 是在檢索階段和 Google 的爬蟲溝通,告知 robots.txt 中的哪些頁面是不希望被檢索、請爬蟲進行封鎖(Disallow)。
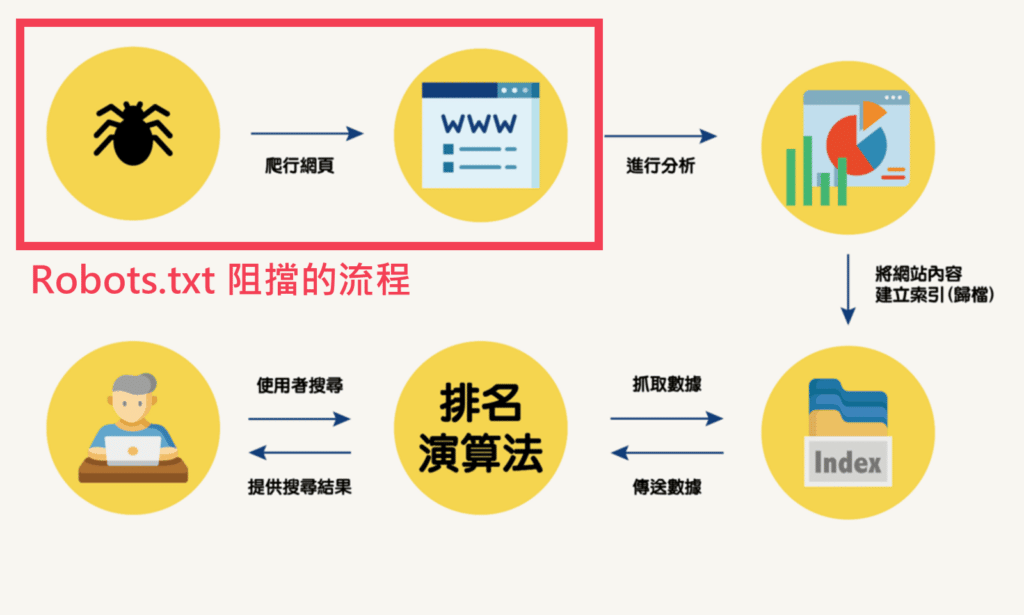
➤ 了解 Google 爬蟲與演算法運作原理這邊請:Google 演算法攻略:演算法邏輯與重大更新解析(2023 更新版)
什麼樣的情境須設定 robots.txt 呢?
通常以下幾個型態的網頁會建議設定於 robots.txt 當中:
- 開發中網頁
- 測試用網頁
- 後台頁面
開發中與測試用的網頁因測試之故所以須安排上線,但其內容尚未開發完善,可能造成使用者體驗不佳,且會耗費爬蟲時間爬取未定案的網頁內容,因此可設定 robots.txt 告知爬蟲不進行爬取;而後台頁面除了內容只開放給內部人員瀏覽外,其內容通常資料結構龐雜(可能有全網站前台顯示的圖片、影片等媒體資料,或其他無關前台使用者體驗的資源檔案),為爬蟲效率考量也建議將該頁面放入 robots.txt 檔案當中。
認識 robots.txt 構成語法參數與設定規範
robots.txt 通常以 5 個語法參數構成:
- User-agent:指定此份 robots.txt 檔案對何種檢索器(爬蟲)生效,看是針對特定檢索器(Googlebot、bingbot 等)、或是針對全檢索器(可直接填入「*」)。
- Allow:允許被檢索的網站內容完整路徑
- Disallow:不允許被檢索的網站內容完整路徑
- Crawl-delay:設定檢索器造訪網站「最短間隔秒數」,以阿拉伯數字填寫。
- Sitemap:Sitemap 放置的完整路徑
以下用一個包含這 5 種語法參數的 robots.txt 檔案舉例:
# robots.txt for https://rankking.works
User-agent: Googlebot
Disallow: /app
Sitemap: https://rankking.works/sitemap.xml
而 Google 官方對於設定 robots.txt 有明確的規範文件,大家在切記要遵守格式撰寫,避免Google 爬蟲無法理解 robots.txt 檔案的內容,導致指令下達失敗的情況喔!以下整理幾個比較重要的規範提供讀者參考:
- 格式須為 UTF-8 字元編碼的純文字檔,勿以文書軟體(如 Word)編檔,因為這類軟體通常會將檔案儲存為某種專有格式,可能因此產生字元符號不相容等問題。
- 內容換行須用 CR、CR/LF、或 LF 等分行字元
- 檔案容量須小於 500 KB
- 檔名須為「robots.tx」(全小寫)
- 一個網站只能有一個 robots.txt 檔案,上傳至網站的根目錄
➤ 延伸閱讀:Sitemap 是什麼?一次掌握 Sitemap 網站地圖製作與提交流程
如何設定 robots.txt?6 個使用情境實際檔案撰寫範例
下列整理 6 種常見的情境與對應的 robots.txt 撰寫範例提供大家參考:
- 「所有」檢索器可檢索「所有」網頁
- 「所有」檢索器不可檢索「所有」網頁
- 「特定」檢索器可檢索「所有」網頁
- 「特定」檢索器不可檢索「所有」網頁
- 「特定」檢索器可檢索「特定」網頁
- 「特定」檢索器不可檢索「特定」網頁
A. 「所有」檢索器可檢索「所有」網頁
說明:不做任何檢索限制
User-agent: *
Disallow:
B. 「所有」檢索器不可檢索「所有」網頁
說明:通常用於測試網站、內部網站,正式網站請避免使用
User-agent: *
Disallow: /
C. 「特定」檢索器可檢索「所有」網頁
說明:下方 robots.txt 情境為「只允許 Googlebot 爬取」
User-agent: Googlebot
Disallow:
D. 「特定」檢索器不可檢索「所有」網頁
說明:下方 robots.txt 情境為「不允許 Googlebot 爬取」
User-agent: *
Disallow: /
E. 「特定」檢索器可檢索「特定」網頁
說明:下方 robots.txt 情境為「只允許 Googlebot 爬取 /blog/ 下的內容 」
User-agent: Googlebot
Allow: /blog/
F. 「特定」檢索器不可檢索「特定」網頁
說明:下方 robots.txt 情境為「不允許 Googlebot 爬取 /blog/ 下的內容 」
User-agent: Googlebot
Disallow: /blog/
如果覺得手動產出 robots.txt 檔案太難太複雜,也可以多加利用 robots.txt 產製工具(robots.txt generator)來加快產出速度喔!
robots.txt 注意事項
除了妥善設定之外,robots.txt 有幾個注意事項需要大家多加留意:
- 並非所有搜尋引擎檢索器(爬蟲)都遵循 robots.txt 的語法,本文主要以目前最大的搜尋引擎 Google 舉例,建議大家如果要操作其他搜尋引擎 SEO 要先確認是否有支援 robots.txt 喔!
- robots.txt 的使用目的主要是以「限制爬蟲爬取比較不重要的葉面以提升效率、節省爬取預算」,並且其效力僅限於「宣告」,本身沒有強制性,因此無法完全禁止爬蟲檢索,故如果要完全阻絕爬蟲,建議使用 Meta robots 的 noindex 語法。
- 若網站是以第三方架站平台(Wordpress、Wix 等)架設,可能無法獲無須自行編輯 robots.txt 檔案,而是有類似功能的設定頁面或機制取代。
robots.txt 檢查工具分享
已上線網站想查看 robots.txt 內容可直接在網址後方加入「/robots.txt」查看。若想測試 robots.txt 檔案,以下整理 2 個 robots.txt 的檢查工具,幫助讀者們快速上手!
- Google Search Console robots.txt 測試工具
- Rankking SEO 網站健檢工具
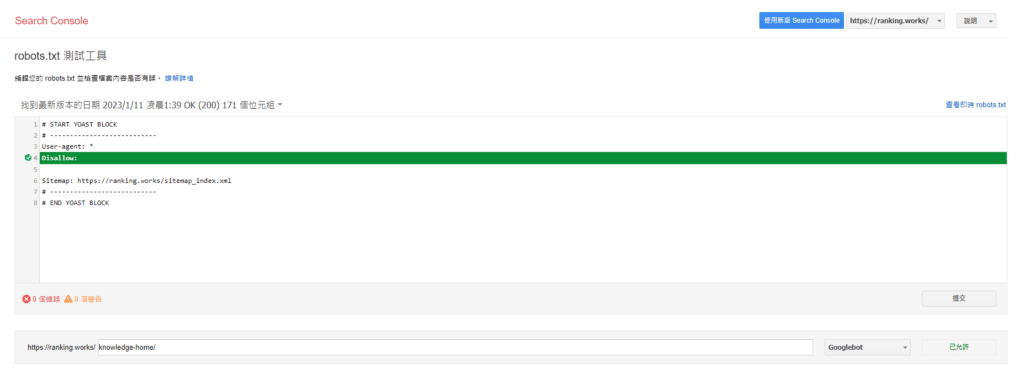
A. Google Search Console robots.txt 測試工具
在 Google Search Console 有提供一個官方的 robots.txt 測試工具,可用於編輯與提交 robots.txt 檔案。另外也提供檢查特定網址是否被爬蟲封鎖的搜尋欄位。
B. Rankking SEO 網站健檢工具
Rankking 提供網站 SEO 健檢報告功能,針對 Google 演算法看重的各項指標提供評分與項目優化建議。其中就包含 robots.txt 的項目檢測,若網站中未有 robots.txt 檔案,也會顯示檢查結果並提示新增;另檢索與索引項目如 Sitemap、Meta robots 標籤(Meta noindex、Meta nofollow)也能一張表格確認。其他如網站安全性、使用體驗等指標也整合於同一個頁面,所有細節一次兼顧。
體驗 SEO 高效檢測:註冊 Rankking SEO 工具享有免費七天體驗!

重要比較資料:robots.txt vs Meta robots noindex 的差異
前文不斷提到的 Meta robots,和 robots.txt 一樣都是對爬蟲檢索與索引下達指令,但是它們的功能和使用方式有所不同:
Meta robots 是一種在網頁代碼 HTML 中所使用的元標籤(meta tag),用於指示搜索引擎如何處理特定網頁的內容。你可以在網頁的 <head> 區域內加入以下標籤:
<meta name=”robots” content=”指令”>
語法中可填入的「指令」最常見的有以下 5 種:
- index:允許搜索引擎索引並顯示該頁面。
- noindex:阻止搜索引擎索引該頁面。
- follow:允許搜索引擎跟隨頁面中的連結。
- nofollow:阻止搜索引擎跟隨頁面中的連結。
- noarchive:阻止搜索引擎建立該頁面的快照存檔。
不同於屬於 HTML 一部分的 meta robots,robots.txt 是一個獨立的文本文件,用於告知搜索引擎爬蟲該如何訪問整個網站的內容。
而其中與 robots.txt 功能最類似、也最常被拿來比較的 meta robots 指令為「noindex」,我們將兩者的功能和設定方法整理為下方表格:
| robots.txt | noindex | |
|---|---|---|
| 主要功能 | 限制爬蟲瀏覽,進而有機會封鎖檢索 | 禁止索引,使設定的頁面不會出現於搜尋結果 |
| 設定方式 | 提交 robots.txt 文字檔於根目錄 | 在想要限制的頁面設定 HTML Meta 標籤 |
若想更了解關於 Meta robots 兩個標籤(noindex、nofollow)的比較,或其他 Meta 標籤的相關說明,歡迎參考以下兩篇文章進行更深入的探討:
➤ Meta robots 說明:【Meta Robots 總整理】透過 Noindex Nofollow 限制爬蟲,強化 SEO 失分漏洞!
➤ Meta 標籤全攻略:【HTML Meta Tags 攻略】掌握 Meta Title & Description,搶佔 SEO 高位!
如何在 WordPress 網站上設定 robots.txt ? 不藏私 robots.txt 教學
在 robots.txt 注意事項的段落中我們有提到:若是使用市面常見架站工具,高機率不需要自己手動設定 robots.txt,而是透過專屬設定頁面或其他替代機制完成。接下來,我們以目前官網或內容型網站最常用的 WordPress 平台為例,教大家如何使用內建的外掛工具完成 robots.txt 設定。以 SEO 操作來說最常使用的 2 個外掛工具如下:
- Yoast SEO 設定 robots.txt
- Rank Math 設定 robots.txt
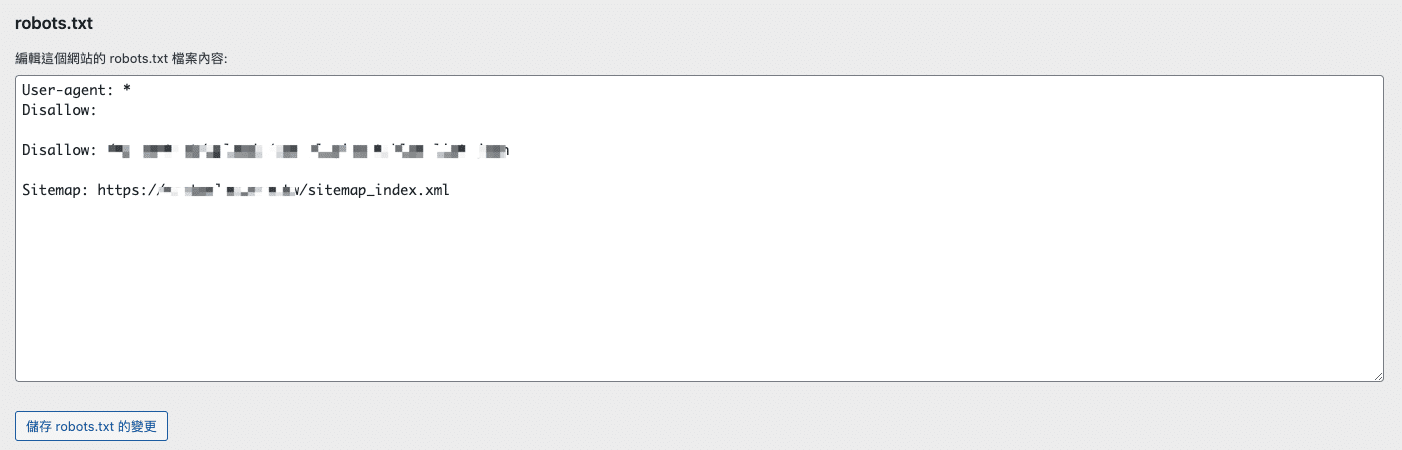
A. Yoast SEO 設定 robots.txt
- 執行路徑:Yoast SEO > 工具 > 編輯檔案
- 點選「檔案編輯器」
- 開始編輯 robots.txt 檔案,按下儲存
B. Rank Math 設定 robots.txt
- 執行路徑:Rank Math >General Settings > Edit robots.txt
- 在右方編輯器中輸入 robots.txt 檔案
- 按下儲存,就完成設定 robots.txt!
![]()
以上是 2 個使用 WordPress 外掛進行設定 robots.txt 的方法,現在就換你動手試看看,替你的 WordPress 網站加入 robots.txt 檔案吧!
同場加映:電商平台該怎麼設定 robots.txt ?
另外要注意的是,如果是使用 91APP、cyberbiz、Shopline 等電商專用的網站系統,會因為每個平台有不同的功能限制,不一定具備設定 robots.txt 的功能。
所以如果身為電商經營者,如果有不希望資料被爬蟲檢索的情況,需要先向電商系統確認是否有支援 robots.txt 功能,或是要使用 meta robots 方式才能阻擋爬蟲爬取資料喔!
robots.txt seo 常見問題:一定要放在根目錄嗎? 一定不會被檢索到嗎?
最後, Rankking 特別整理兩個大家在執行 SEO 時最常問到的 robots.txt 相關問題,幫助大家更完整的掌握 robots.txt 的實務應用:
- robots.txt 一定要放在網站的根目錄嗎?
- 使用 robots.txt 禁止某頁面被檢索,該頁面就一定不會被索引嗎?
A. robots.txt 一定要放在網站的根目錄嗎?
robots.txt 不一定要放在網站的根目錄下,但是放在根目錄下是最推薦的做法,因為搜索引擎會預設在網站的根目錄爬取這個檔案。
如果你希望 robots.txt 放在不同的位置,可以在網站根目錄的 robots.txt 文件中使用以下指令,來指示爬蟲尋找正確的 robots.txt 位置:
Sitemap: https://www.example.com/your-custom-location/robots.txt
告訴爬蟲在指定的位置找到 robots.txt 。但是這可能會增加爬蟲尋找的時間,所以為了確保搜能夠快速找到並正確解析 robots.txt 文件,放在網站的根目錄是一個最推薦、可靠的方法。
B. 使用 robots.txt 禁止某頁面被檢索,該頁面就一定不會被索引嗎?
不一定。robots.txt 文件中的指令是一種建議,而不是絕對的限制。雖然大多數搜索引擎會遵循 robots.txt 中的指令,但並不是所有搜索引擎都會嚴格遵循這些規則。
另外,即使爬蟲遵照 robots.txt 文件中的指令,仍然可能存在一些情況,導致頁面被意外地索引,例如:
- 已經索引的頁面: 如果某個頁面已經被搜索引擎索引,並且之後才在 robots.txt 文件中禁止檢索,搜索引擎可能仍然會顯示該頁面的索引結果,直至重新索引該頁面。
- 其他網站的連結: 即使已在網站上禁止了某個頁面被檢索,如果其他網站上有指向該頁面的連結,搜索引擎可能會通過這些外部連結找到該頁面並進行索引。
- 搜索引擎不尊重 robots.txt: 一些搜索引擎或爬蟲可能會忽略 robots.txt 文件中的指令,或者錯誤地解釋規則,導致頁面被索引。
綜合上述,使用 robots.txt 文件可以有效地控制爬蟲的訪問和索引,但並不是絕對可靠的方法。如果您希望某個頁面絕對不要被索引,最好的方式是使用其他方法,例如使用noindex指令來標記頁面。
robots.txt seo 設定,就用 Rankking AI SEO 工具全方面解決問題
SEO 行銷的專家品牌 Rankking,以「行銷科技創新、簡單好上手、排名不斷成長」3大訴求出發,推出 Rankking AI SEO 工具,協助客戶檢查網站 SEO 功能,包括 robots.txt 、 XML Sitemap 、 Meta noindex、內容分析、網站安全性 ,一鍵快速檢測網站優化方針。
Rankking AI SEO 工具:你的智能優化管家,現在註冊享免費 7 天體驗!