
在 robots.txt 一文中我們提到,robots.txt 的文件是為了限制爬蟲檢索網頁的範圍,藉以提升爬蟲爬取網頁的效率,幫助我們進行 SEO 操作。那不免會延伸出這樣的疑問:robots.txt 僅限制爬蟲檢索,無法直接限制網頁不出現在搜尋結果頁,該做什麼設定才能達到這樣的效果呢?這便是今天要介紹的主題:Meta Robots 的兩個重要標籤,Noindex 與 Nofollow。以下將介紹兩個語法屬性的基本概念、實際撰寫案例,以及 Meta Robots 與 robots.txt 的綜合比較!
➤ 想了解爬蟲與演算法運作請參考:Google 演算法攻略:演算法邏輯與重大更新解析(2023 更新版)
什麼是 Noindex?限制爬蟲索引的重要標籤!
Noindex 屬於 Meta Robots 的一種標籤屬性,而 Meta Robots 是設定於 HTML 語法 <head> 中的一種標籤。其主要功能是用以和 Google 爬蟲溝通,告知爬蟲不要索引特定網頁,進而不要將該網頁顯示於搜尋結果之中。
➤ Meta 標籤全攻略:【HTML Meta Tags 攻略】掌握 Meta Title & Description,搶佔 SEO 高位!
一、什麼類型的頁面會設定 Noindex?視 SEO 重要性而定!
那麼什麼樣的頁面會建議設定 Noindex 呢?我們歸納了以下三種類型的頁面:
- 法律規定須存在但無助於 SEO 的頁面:隱私權條款頁、智慧權財產頁等
- 使用者流程重要頁面,但不適合對外公布:購物車頁面、結帳頁面等
- 半完成頁面,會降低使用者體驗:開發中的頁面、測試用頁面等
可以看到以上的頁面都是無關乎 SEO 或會讓使用者體驗不佳的頁面,這種類型的網頁都建議不要顯示在搜尋結果頁上,對於 SEO 的操作會比較好喔!
二、重要概念釐清:Noindex vs. robots.txt,用法差異與使用時機
Noindex 與 robots.txt 都是限制爬蟲的行為,這兩者在用法與時機上究竟有何差異呢?我們不妨從 Noindex 在 Google 官方文件上的說明來找答案:
Googlebot 在檢索網頁並看到 noindex 標記時,就會將網頁排除在搜尋結果之外,不論是否有其他網站連結到該網頁都一樣。
robots.txt 雖然能告知爬蟲勿檢索某個網頁,但仍有以下三個注意事項:
- 對爬蟲無強制力,文件格式錯誤甚至會直接被爬蟲忽略
- 若有其他網站連結到已設定 robots.txt 的網頁,該網頁仍會透過此連結被爬蟲索引
- 最後,robots.txt 的主要目的本不是限制檢索,而是透過限制檢索提升爬取效率
綜合以上三點可以得知,robots.txt 和 Noindex本質上是為了不同的目的(提升爬蟲效率 v.s. 排除特定網頁),只是剛好透過封鎖爬蟲檢索或索引的方式進行,從易於混淆。因此在使用時機上,我們根據上方的資訊提出簡單好記的結論:會影響爬蟲效率的網頁,請用 robots.txt;會影響 SEO 排名或使用者體驗的網頁,請用 Noindex。
什麼是 Nofollow?限制惡意連結瓜分網站權重!
Nofollow 和 Noindex 一樣屬於 Meta Robots 的一種標籤,簡單用一句話說明其功用,就是防止低權重的網頁「蹭權重」。在介紹 Nofollow 前,首先先帶大家以 SEO 的角度了解網站權重的運作方式。
一、何謂網站權重?網站權重轉移的機制又是如何運作呢?
Google 仰賴演算法來判斷網頁排名的高下,其中一個重要的指標即是「網站權重」,可以理解成你的網站的「品質」、「權威性」。若你的網站內容被很多其他網站引用,則爬蟲可能會認為:這個網站被其他網站背書,因此你的網站相對有價值或解決了大多數人的問題。
舉例來說,今天 Ranking 的 SEO 文章被許多關於 SEO 的網站提到或引用,表示其他網站認可我們的文章內容是有價值且有參考性的,因此才會轉發布在自己的網站上。這對搜尋引擎來說無異於提升了我們網站的權重。
而網站權重轉移的運作,以上述 Ranking SEO 文章的情境,若 A 網站引用了 Ranking 的文章連結(對 Ranking 來說,這組連結為「反向連結(Backlinks)」),則可視為 A 網站認可 Ranking,因此 A 網站的部分權重會藉由連結被分配給 Ranking;相反地,若 Ranking 在自己的網站中引述了 B 網站的連結,也會分配部分權重給 B 網站。

➤ 深入了解網站權重:什麼是網域權威 DA (Domain Authority)?他在 SEO 排名上有什麼幫助?
➤ 網頁連結概念大全:【網頁連結優化】外部連結、內部連結怎麼做?佈局網站連結優化策略!
二、Nofollow 是網頁權重的守門員!
當我們的網站擁有較佳的權重和排名時,便有機會被其他網站透過在留言區留下連結、程式產出大量外部網址等的方式試圖瓜分網站權重,也就是我們說的「蹭權重」。
Nofollow 語法就是為了因應這種狀況而生的!若某網頁在 HTML <head> 中設定了 Meta Robots Nofollow 便是在告訴搜尋引擎:網頁上的這些外部連結都不要檢索、不要分配權重出去(僅為參考資料,我不為其權威背書的意思)。
延續上述的例子,若 Ranking 在引述其他網站的網頁設定 Nofollow,則我們網站的權重就不會被這個連結分享出去。Nofollow 可視為網頁權重的守門員,阻擋惡意連結的刻意瓜分。

三、Meta Robots Nofollow vs. rel=”nofollow” 概念比較
Meta Robots Nofollow 是在 HTML <head> 中設定,直接將全頁面所有外部連結無差別禁止檢索;但有時並非所有外部連結都需要 Nofollow,可能只有單一連結需要被封鎖,這時我們就能針對這樣的單一連結設定 rel=”nofollow” 屬性。
舉例來說,今天我在這篇文章引述了麥當勞的官網,但我並不希望替麥當勞網站背書、讓他們分配我網站的權重,我便可以僅針對麥當勞官網連結設定 rel=”nofollow”,HTML 語法撰寫範例如下:
(Meta Robots Nofollow 語法撰寫範例請參下一段落)
<a href=”https://www.mcdonalds.com/tw/zh-tw.html″ rel=”nofollow”>
四、rel=”nofollow” 議題升級:外部連結的性質區分
約莫在 2004 年推出 rel=”nofollow” 屬性後,Google 為應對越來越多的連結類型,新增了不同的連結屬性,能夠幫助網站主去區分不同情境的連結、並提供相關屬性資料給爬蟲參考:
1. rel=”sponsored”-付費連結
<a href=”https://www.mcdonalds.com/tw/zh-tw.html″ rel=”sponsored”>
sponsored 屬性代表該連結是網站上做為廣告、贊助或其他報酬協議的一部分。
若麥當勞有付費請我們建立這組連結在網站上,即可用此屬性標示。
2. rel=”ugc”-使用者產製的內容
<a href=”https://www.mcdonalds.com/tw/zh-tw.html″ rel=”ugc”>
ugc 屬性代表使用者自製內容,例如論壇留言區的留言有提到外部連結,即可使用此屬性。
若 Ranking 有留言區,且有使用者來留言麥當勞的連結,我們即會在留言區設定此屬性。
Meta Robots Noindex 與 Nofollow 實際語法撰寫案例
了解了 Meta Robots Noindex Nofollow 的概念後,以下我們整理了實際撰寫 HTML Meta Robots Tags 的四種情境和語法撰寫範例,讓我們先從參數開始吧!
一、HTML Meta Robots Tags 參數說明
Meta Robots Tags 主要有以下幾個項目:
1. Meta Name:Meta Tags 的項目名稱,此處應填入「robots」
2. Content:Meta Robots 需執行的內容,又分為以下兩個參數、四個狀態:
- Noindex:此頁面限制建立索引
- Index:此頁面允許建立索引
- Nofollow:此頁面上的外部連結,限制檢索
- Follow:此頁面上的外部連結,允許檢索
二、Noindex 與 Nofollow 4 種不同情境案例
針對不同頁面而設置不同的 Noindex 、 Nofollow 語法組合,能讓網站中的各頁面各別經過調整後,提升搜尋引擎上的排名表現。
1. Index Follow:允許頁面索引、允許連結檢索
用於要操作 SEO 的頁面,Index 和 Follow 通常不會特別設定 Meta Robots Tags,因為即便沒設定爬蟲也會執行這兩個動作。
<meta name=”robots″ content=”index,follow”>
2. Noindex Follow:限制頁面索引、允許連結檢索
用於法規政策頁面,或非重要資訊的頁面,顯示於搜尋結果頁上對於爬蟲和使用者沒有幫助,但若法規內容有引述其他重要平台則可讓爬蟲檢索外部連結,進而建立關聯性。
<meta name=”robots″ content=”noindex,follow”>
3. Index Nofollow:允許頁面索引、限制連結檢索
用於評論頁面、論壇留言區,這些資訊呈現於搜尋結果頁對於網站有所幫助;但其連結易被惡意操作,因此須限制。
<meta name=”robots″ content=”index,nofollow”>
4. Noindex Nofollow:限制頁面索引、限制連結檢索
常用於購物車、結帳等消費流程頁面,或系統後台頁等會消耗爬蟲效率且內容對 SEO 排名也沒有幫助的頁面。
<meta name=”robots″ content=”noindex,nofollow”>
Meta Robots 與 robots.txt 總整理:功能、使用方式與語法
介紹完以上所有資訊後,Ranking 整理了一份比較 Meta Robots Noindex Nofollow 與 robots.txt 這三個易混淆的設定,希望對於讀者們釐清概念上更有幫助喔!
| 設定項目 | Meta Robots | robots.txt | |
|---|---|---|---|
| Noindex | Nofollow | ||
| 主要功能與目的 | 限制爬蟲索引頁面,避免頁面被排名。 | 限制爬蟲檢索頁面上的外部連結,避免權重瓜分。 | 限制爬蟲爬取特定頁面,提升爬取效率。 |
| 使用方式 |
設定於 HTML Meta Tags 中 |
將 robots.txt 檔案上傳至網站根目錄 | |
|
對於爬蟲階段之作用 |
|||
| 檢索(Crawling) | 允許 | 允許 |
限制 (但非強制*) |
| 索引(Indexing) | 限制 | 允許 |
限制爬蟲爬取 故不會建立索引 |
| 顯示於 SERP | 限制 | 允許 |
沒有建立索引的網頁 不會顯示於 SERP 上 |
*注:robots.txt 在實務運作上僅能向 Google 爬蟲做出「不要爬取」的宣告,但此宣告並沒有強制性,故就算設定 robots.txt 網頁仍可能被爬蟲爬取,進而發生被索引與出現於 SERP 上的狀況(舉例來說,A網頁設定了 robots.txt 但 B 網頁放置了連結連到 A 網頁,此時爬蟲仍可能透過 B 網頁找到 A 網頁並建立索引)。若想完全杜絕特定網頁出現在 SERP 上,需搭配 noindex 使用。
Noindex Nofollow 測試工具分享
一、Google Nofollow 工具:檢測 rel=”nofollw”
Google 提供一組 Chrome Nofollow 外掛工具,可以快速網頁上的連結是否設定 Nofollow。若有設定 Nofollow,則會顯示紅框。
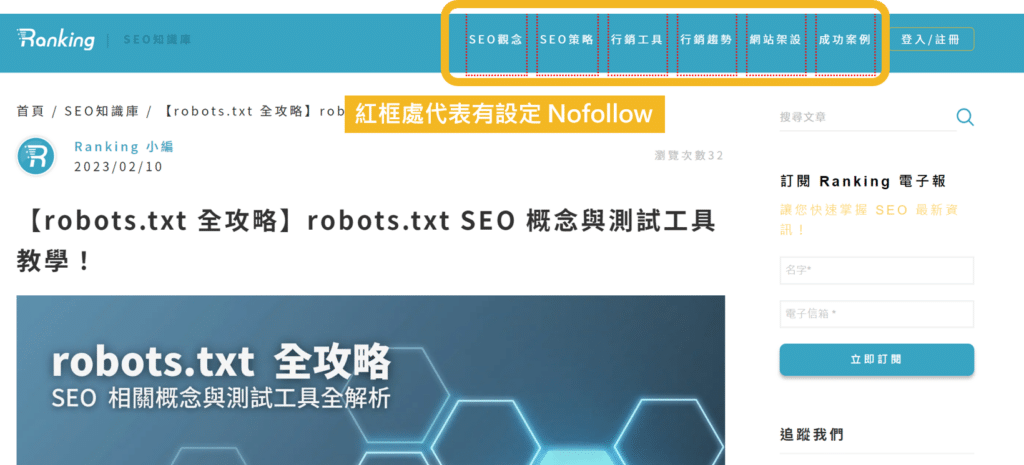
二、Ranking SEO 網站健檢:檢測 Noindex Nofollow
Ranking 提供網站 SEO 健檢報告功能,針對 Google 演算法看重的各項指標提供評分與項目優化建議。其中包含了 Meta Robots 的 Noindex 與 Nofollow 屬性檢查,是否有設定這兩個屬性在一張表格中一目了然!而其他指標如 robots.txt 檔案、Sitemap、網站安全性、使用體驗等也整合於同一個頁面,所有細節一次兼顧。

➤ 體驗強效 SEO 助手:Ranking 工具註冊免費體驗 7 天試用
結論
以上為針對 Meta Robots 的相關資訊,若想了解更多 SEO 相關的技術可以瀏覽 Ranking SEO 知識庫中的文章。SEO 技術操作對於剛接觸這塊領域的 SEOer 來說門檻可能較高,Ranking 亦有專業的 SEO 專案服務,強效的團隊從技術到策略面一條龍整合,歡迎參考 Ranking 服務方案!
